Hands-on CamemBERT: Une Introduction au Modèle CamemBERT
![]()
Ce tutoriel a été conçu dans le cadre des journées Deep Voice de l’IRCAM par Roman Castagné, Nathan Godey et Benjamin Muller.
Une version du tutoriel en anglais en version pdf slide est disponible ici, ainsi que le même tutoriel dans Google Colab.
Cet atelier présente le modèle de langue CamemBERT et différents cas d’usage. Nous allons nous intéresser particulièrement au cas de la classification d’acte de dialogue.
Dans ce Tutoriel:
Ce tutoriel est une introduction au Natural Language Processing et en particulier au modèle de langue de type BERT.
Objectifs
- Comprendre le fonctionnement du modèle CamemBERT.
- Apprendre à construire un modèle pour une tâche spécifique de NLP avec CamemBERT.
Pour cela
Nous allons nous intéresser à une tâche de classification de séquence: la tâche de prédiction d’acte de dialogue.
Nous allons utiliser le dataset MIAM (introduis ici) afin d’entraîner et d’évaluer nos modèles sur cette tâche.
Nous travaillerons avec la librairie transformers de Hugging-Face 🤗 ainsi que la librairie pytorch-lightning.
Cette mise en pratique se fera en deux parties:
- (Partie 1) Comprendre la modélisation du français par Camembert
- (Partie 2) Fine-tuning : comment ré-entraîner CamemBERT sur nos données pour répondre à notre tâche de classification d’acte de dialogue? Pour passer directement à la deuxième partie c’est par ici
Prérequis
- bases en python
- bases en machine learning
La première étape est l’installation et l’importation des librairies utilisées dans la suite de l’atelier. Certaines librairies (torch, numpy, sklearn, …) sont pré-installées dans l’environnement de Google Colab, nous n’avons donc pas besoin de nous en occuper.
!pip install transformers plotly==5.8.0 pyyaml==5.4.1 datasets pytorch-lightning > /dev/null 2>&1
from pprint import pprint
import functools
import torch
from torch.utils.data import DataLoader
import torch.nn.functional as F
import pytorch_lightning as pl
from transformers import AutoModelForSequenceClassification, CamembertForMaskedLM, AutoTokenizer, AutoConfig
from datasets import load_dataset
from sklearn.metrics import confusion_matrix, f1_score
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
from tqdm.notebook import tqdm
Partie 1: Comprendre la modélisation du français par CamemBERT
Rentrons dans le vif du sujet et téléchargeons le modèle CamemBERT grâce à la librairie HuggingFace, il suffit d’une ligne:
camembert = CamembertForMaskedLM.from_pretrained('camembert-base')
HuggingFace est une bibliothèque en ligne gratuite de modèles pré-entraînés et de jeux de données (datasets) qui permet d’utiliser les architectures et les poids des modèles mis à disposition par les équipes de recherche / institutions. Nous vous invitons à faire un tour sur leur plateforme, sur laquelle il est possible de rechercher:
L’architecture de Camembert: le Transformer
Le Transformer est une architecture deep learning introduite en 2017 dans l’article Attention Is All You Need. Il permet de traiter des séquences dont les éléments sont fortement inter-dépendants, comme c’est le cas pour les mots d’une phrase par exemple.
CamemBERT-base (la version base du modèle) est composé:
- d’une couche d’embedding pour représenter chaque mot en vecteur
- de 12 couches cachées composées principalement de deux types de transformations: des transformations dites self-attention et des transformations denses
Schématiquement:
![]()
# Visualiser la couches d'embeddings
camembert.roberta.embeddings
RobertaEmbeddings(
(word_embeddings): Embedding(32005, 768, padding_idx=1)
(position_embeddings): Embedding(514, 768, padding_idx=1)
(token_type_embeddings): Embedding(1, 768)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
Dans le résultat de la cellule ci-dessus, on peut voir que la couche d’embedding (RobertaEmbeddings) stocke 32005 vecteurs de dimension 768 (word_embeddings). Chacun de ces vecteurs est associé à un mot du vocabulaire du modèle.
Les position embeddings renseignent quant à eux sur la position d’un mot dans la séquence d’entrée.
# Visualiser les couches cachées
print(f"Camembert est composé de {len(camembert.roberta.encoder.layer)} couches cachées\n")
print("Composition de la première couche :")
camembert.roberta.encoder.layer[0]
Camembert est composé de 12 couches cachées
Composition de la première couche :
RobertaLayer(
(attention): RobertaAttention(
(self): RobertaSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): RobertaSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): RobertaIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): RobertaOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
Dans la plupart des couches du modèle, les vecteurs utilisés sont de dimension 768. C’est ce qu’on appelle la dimension cachée du modèle.
Nous pouvons aussi calculer le poids total du modèle en MB:
def display_nb_params(model):
param_size = 0
param_count = 0
for param in model.parameters():
param_count += param.nelement()
param_size += param.nelement() * param.element_size()
buffer_size = 0
for buffer in model.buffers():
buffer_size += buffer.nelement() * buffer.element_size()
size_all_mb = (param_size + buffer_size) / 1024**2
print('Nombre de paramètres: {} | Poids du modèle: {:.2f}MB'.format(param_count, size_all_mb))
display_nb_params(camembert)
Nombre de paramètres: 110655493 | Poids du modèle: 422.13MB
Faire des Prédictions avec CamemBERT en mode modèle de langue
Avant d’utiliser le modèle CamemBERT pour la classification de phrases, nous allons étudier les différentes étapes qui permettent de passer d’une phrase (sous la forme d’une chaîne de caractères) à une prédiction.
Le modèle que nous avons téléchargé est pré-entraîné avec une tâche de Masked Language Modelling : certains mots ou sous-mots de la séquence sont masqués et on demande au modèle de les prédire à partir du contexte (les mots non-masqués).
Considérons un exemple simple dans lequel nous voulons compléter 3 phrases dans lesquelles nous avons masqué un mot:
batch_sentences = [
"Vous savez où est la <mask> la plus proche?",
"La Seine est un <mask>.",
"Je cherche urgemment un endroit où retirer de l'<mask>.",
]
La première étape consiste à tokeniser les chaînes de caractères. Il s’agit de découper les phrases d’entrée en mots et sous-mots (appelés tokens) issus d’un vocabulaire extrait à l’aide de l’algorithme Sentencepiece (article de blog pour plus de détails).
Chaque token est ensuite identifié à l’aide d’un entier correspondant à sa position dans le vocabulaire (input_ids) et un masque indique sur quels tokens l’attention doit se porter dans chaque phrase (attention_mask):
tokenizer = AutoTokenizer.from_pretrained('camembert-base')
tokenizer_output = tokenizer(
batch_sentences
)
pprint(tokenizer_output, width=150)
{'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
'input_ids': [[5, 158, 2591, 147, 30, 13, 32004, 13, 40, 1084, 197, 6],
[5, 61, 4458, 30, 23, 32004, 21, 9, 6],
[5, 100, 1066, 21, 20090, 10256, 23, 1643, 147, 4384, 8, 17, 11, 32004, 21, 9, 6]]}
On note que le tokenizer associé à CamemBERT peut lui aussi être téléchargé depuis HuggingFace.
Nous pouvons décoder les input_ids afin d’observer le comportement du tokenizer, notamment la manière dont il segmente le mot urgemment en deux tokens: urge et mment:
pprint([tokenizer.convert_ids_to_tokens(input_ids) for input_ids in tokenizer_output['input_ids']], width=150)
[['<s>', '▁Vous', '▁savez', '▁où', '▁est', '▁la', '<mask>', '▁la', '▁plus', '▁proche', '?', '</s>'],
['<s>', '▁La', '▁Seine', '▁est', '▁un', '<mask>', '▁', '.', '</s>'],
['<s>', '▁Je', '▁cherche', '▁', 'urge', 'mment', '▁un', '▁endroit', '▁où', '▁retirer', '▁de', '▁l', "'", '<mask>', '▁', '.', '</s>']]
On remarque aussi que les espaces ont été remplacés par des caractères spéciaux (▁). Deux tokens ont été ajoutés: un token de début de séquence <s>, et un token de fin de séquence </s>.
Cette tokenisation n’est pas adaptée dans notre cas: les couches Transformers du modèle CamemBERT traitent des séquences de longueur fixe (ici 512). Il faut donc ajouter des tokens de padding, qui complètent les séquences:
tokenizer_output = tokenizer(
batch_sentences,
padding="max_length"
)
pprint(tokenizer_output, compact=True, width=150)
{'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'input_ids': [[5, 158, 2591, 147, 30, 13, 32004, 13, 40, 1084, 197, 6, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[5, 61, 4458, 30, 23, 32004, 21, 9, 6, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[5, 100, 1066, 21, 20090, 10256, 23, 1643, 147, 4384, 8, 17, 11, 32004, 21, 9, 6, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
L’attention_mask permet de garder en mémoire la position des tokens de padding dans chaque séquence.
Il faut enfin s’assurer qu’aucune séquence ne dépasse cette limite de 512 tokens. Il suffit pour cela d’indiquer truncation=True au tokenizer, qui tronquera alors toutes les séquences à la longueur appropriée.
Enfin, comme nous allons utiliser la librairie PyTorch pour réaliser les calculs vectoriels et matriciels, nous devons convertir les sorties du tokenizer en torch.Tensor avec l’argument return_tensors='pt' (pour PyTorch).
tokenizer_output = tokenizer(
batch_sentences,
padding="max_length",
truncation=True,
return_tensors="pt"
)
pprint(tokenizer_output, width=150)
{'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]]),
'input_ids': tensor([[ 5, 158, 2591, ..., 1, 1, 1],
[ 5, 61, 4458, ..., 1, 1, 1],
[ 5, 100, 1066, ..., 1, 1, 1]])}
Le pre-processing est terminé! Nous pouvons maintenant donner le contenu du dictionnaire issu du tokenizer comme arguments d’entrée du model:
with torch.no_grad():
model_output = camembert(**tokenizer_output, output_hidden_states=True)
model_output
Le modèle a renvoyé un tenseur de logits. Mais qu’est-ce que des logits ?
Les logits sont des scores attribués aux tokens du vocabulaire pour chaque position de la séquence. Le modèle CamemBERT a été entraîné à prédire les tokens remplacés par [MASK], et donc à attribuer des logits plus élevés aux tokens d’origine aux positions masquées.
En appliquant la fonction Softmax aux logits, on peut prédire les probabilités associées à chaque token en sortie du modèle. Ainsi, pour une phrase donnée:
P(phrase[k] = vocab[i]) = softmax(logits[k])[i]
Pour rappel, la fonction softmax est:
$$ \text{softmax}(s) = \left( \frac{e^{s_i}}{\sum_k e^{s_k}} \right)_{i\in[|1,K|]} \text{for } s\in \mathbb{R}^K.$$
Pour chaque phrase du batch, nous avons donc un vecteur de logits par token. Ces vecteurs ont autant de coordonnées qu’il y a de dimensions dans le vocabulaire.
Le tenseur complet de logits est donc de dimension nb_batchs x longueur_seq x taille_vocab:
model_output.logits.shape # 3 phrases, 512 tokens (après tokenization + padding), 32005 tokens possibles
torch.Size([3, 512, 32005])
Calculons donc les probabilités issues du modèle à l’aide de la méthode softmax de Pytorch:
def get_probas_from_logits(logits):
return logits.softmax(-1)
def visualize_mlm_predictions(tokenizer_output, model_output, tokenizer, nb_candidates=10):
# Decode the tokenized sentences and clean-up the special tokens
decoded_tokenized_sents = [sent.replace('<pad>', '').replace('<mask>', ' <mask>') for sent in tokenizer.batch_decode(tokenizer_output.input_ids)]
# Retrieve the probas at the masked positions
masked_tokens_mask = tokenizer_output.input_ids == tokenizer.mask_token_id
batch_mask_probas = get_probas_from_logits(model_output.logits[masked_tokens_mask])
for sentence, mask_probas in zip(decoded_tokenized_sents, batch_mask_probas):
# Get top probas and plot them
top_probas, top_token_ids = mask_probas.topk(nb_candidates, -1)
top_tokens = tokenizer.convert_ids_to_tokens(top_token_ids)
bar_chart = px.bar({"tokens": top_tokens[::-1], "probas": list(top_probas)[::-1]},
x="probas", y="tokens", orientation='h', title=sentence, width=800)
bar_chart.show(config={'staticPlot': True})
visualize_mlm_predictions(tokenizer_output, model_output, tokenizer)
Représentation de phrases avec Camembert
Comment représenter des phrases ?
Nous avons vu dans la première partie comment CamemBERT est capable de traiter du langage naturel au niveau des mots (ou plus précisément des tokens). Nous allons maintenant voir comment il est possible de traiter le langage naturel au niveau des phrases à l’aide du même modèle.
Pour rappel, CamemBERT associe à chaque token un embedding - un vecteur en haute dimension, ici 768 - dépendant notamment du contexte dans lequel ce token se trouve. Ces embeddings sont en réalité les vecteurs pris en entrée de la couche lm_head, que l’on peut obtenir ainsi:
token_embeddings = model_output.hidden_states[-1]
QUESTION 4 : Quelle sont les dimensions du tenseur token_embeddings ?
Comment pouvons-nous représenter une phrase (c’est-à-dire une séquence de tokens) à l’aide de ces embeddings de tokens ?
Deux solutions sont habituellement retenues:
- Représenter la phrase en extrayant l’embedding du premier token, qui dans le cas de CamemBERT est toujours le token
<s> - Représenter la phrase en réalisant la moyenne des embeddings de tous les tokens de la séquence
Ces deux méthodes sont implémentées dans la cellule suivante:
def take_first_embedding(embeddings, attention_mask=None):
return embeddings[:, 0]
def average_embeddings(embeddings, attention_mask):
return (attention_mask[..., None] * embeddings).mean(1)
Nous pouvons donc récupérer les représentations pour chacune des méthodes, et vérifier que les tenseurs ont bien la bonne forme en sortie, correspondant à batch_size x hidden_size (un vecteur par phrase dans le batch):
first_tok_sentence_representations = take_first_embedding(token_embeddings, tokenizer_output.attention_mask)
avg_sentence_representations = average_embeddings(token_embeddings, tokenizer_output.attention_mask)
first_tok_sentence_representations.shape, avg_sentence_representations.shape
(torch.Size([3, 768]), torch.Size([3, 768]))
Il est possible de mesurer la similarité entre ces deux représentations à l’aide de n’importe quelle distance (euclidienne, absolue, …), mais c’est généralement la cosine-similarity qui est retenue.
Cette similarité peut donner une idée de la similarité sémantique et/ou linguistique entre deux phrases, mais sa fiabilité n’est pas absolue.
Sa valeur, comprise entre -1 et 1, renseigne sur l’écart angulaire entre les deux embeddings. Nous pouvons l’utiliser pour comparer deux à deux nos embeddings issus du batch:
for sent_id_1, sent_id_2 in [[0, 1], [2, 1], [2, 0]]:
first_tok_similarity_score = F.cosine_similarity(first_tok_sentence_representations[sent_id_1], first_tok_sentence_representations[sent_id_2], dim = -1)
avg_similarity_score = F.cosine_similarity(avg_sentence_representations[sent_id_1], avg_sentence_representations[sent_id_2], dim = -1)
print(f"{batch_sentences[sent_id_1]} vs. {batch_sentences[sent_id_2]}")
print(f"Score (first_tok) : {first_tok_similarity_score}")
print(f"Score (average) : {avg_similarity_score}\n")
Vous savez où est la <mask> la plus proche? vs. La Seine est un <mask>.
Score (first_tok) : 0.9248192310333252
Score (average) : 0.8208701610565186
Je cherche urgemment un endroit où retirer de l'<mask>. vs. La Seine est un <mask>.
Score (first_tok) : 0.9264650344848633
Score (average) : 0.8607435822486877
Je cherche urgemment un endroit où retirer de l'<mask>. vs. Vous savez où est la <mask> la plus proche?
Score (first_tok) : 0.9239857196807861
Score (average) : 0.8845345973968506
On remarque que l’approche consistant à choisir l’embedding du premier token pour représenter une phrase ne permet pas de différencier les niveaux de similarité entre les phrases. Pour l’inférence, on préférera donc faire la moyenne des embeddings, qui donne une plus grande similarité entre les phrases les plus proches sémantiquement.
Application à des messages de chats
Maintenant que nous avons pris en main le modèle CamemBERT, nous allons voir comment l’utiliser sur des données réelles.
Pour cet atelier, nous allons utiliser le split français du dataset MIAM, qui regroupe des messages extraits d’une plateforme de chat, accompagnés de labels décrivant une intention propre au message.
Ce dataset est disponible sur HuggingFace, et on peut le télécharger grâce à la fonction load_dataset:
dataset = load_dataset("miam", "loria")
dataset
DatasetDict({
train: Dataset({
features: ['Speaker', 'Utterance', 'Dialogue_Act', 'Dialogue_ID', 'File_ID', 'Label', 'Idx'],
num_rows: 8465
})
validation: Dataset({
features: ['Speaker', 'Utterance', 'Dialogue_Act', 'Dialogue_ID', 'File_ID', 'Label', 'Idx'],
num_rows: 942
})
test: Dataset({
features: ['Speaker', 'Utterance', 'Dialogue_Act', 'Dialogue_ID', 'File_ID', 'Label', 'Idx'],
num_rows: 1047
})
})
Il est possible de convertir ce dataset en pandas.DataFrame:
pd_dataset = {split_name: split_data.to_pandas() for split_name, split_data in dataset.items()}
pd_dataset["validation"]
| Speaker | Utterance | Dialogue_Act | Dialogue_ID | File_ID | Label | Idx | |
|---|---|---|---|---|---|---|---|
| 0 | Samir | Bravo! Vous avez été rapides! | greet | 19 | Dial_20110530_154627 | 5 | 0 |
| 1 | Samir | Qu'est-ce que je peux faire pour vous? | ask | 19 | Dial_20110530_154627 | 1 | 1 |
| 2 | Julie | merci | next_step | 19 | Dial_20110530_154627 | 17 | 2 |
| 3 | Samir | Eh bien, il va falloir la fabriquer cette mane... | inform | 19 | Dial_20110530_154627 | 7 | 3 |
| 4 | Samir | Mais sinon, vous avez encore des questions sur... | ask | 19 | Dial_20110530_154627 | 1 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 937 | Julie | Avec plaisir! | yes | 1239 | Dial_20120104_160514 | 30 | 937 |
| 938 | Sophia | C' est un métier pour lequel il faut être poly... | inform | 1239 | Dial_20120104_160514 | 7 | 938 |
| 939 | Julie | Oui, je vois. | ack | 1239 | Dial_20120104_160514 | 0 | 939 |
| 940 | Sophia | Je vous laisse les assembler , je les ai posé ... | quit | 1239 | Dial_20120104_160514 | 21 | 940 |
| 941 | Julie | Ok. Merci! à toute! | quit | 1239 | Dial_20120104_160514 | 21 | 941 |
942 rows × 7 columns
Explorons ce dataset. Dans un premier temps, on peut étudier la répartition des labels:
nb_labels = len(pd_dataset["train"]["Label"].unique())
print(f"Le dataset comprend {nb_labels} labels.")
ax = pd_dataset["train"]["Label"].hist(density=True, bins=nb_labels+1)
ax.set_xlabel("Label ID")
ax.set_ylabel("Fréquence")
ax.set_title("Répartition des labels dans le dataset MIAM (train split)")
ax.figure.show()
Le dataset comprend 31 labels.
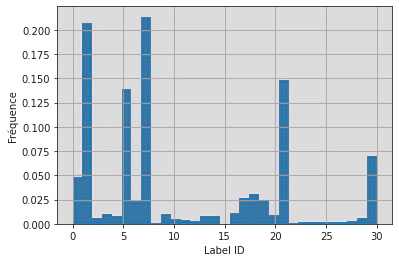
Ce dataset est donc assez déséquilibré. On peut ensuite s’intéresser à la longueur des chaînes de caractères et vérifier qu’elles sont adaptées à l’utilisation de CamemBERT:
pd_dataset["train"]["len_utt"] = pd_dataset["train"]["Utterance"].apply(lambda x: len(x))
ax = pd_dataset["train"]["len_utt"].hist(density=True, bins=50)
ax.set_xlabel("Longueur")
ax.set_ylabel("Fréquence")
ax.set_title("Nombre de caractères par phrase")
ax.figure.show()
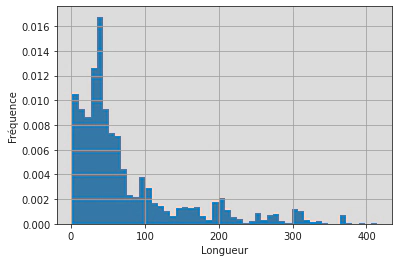
Notamment, aucune phrase ne comporte plus de 512 caractères, et donc aucune phrase ne comportera plus de 512 tokens:
print((pd_dataset["train"]["len_utt"] > 512).any())
False
Utilisons maintenant CamemBERT afin d’obtenir une représentation vectorielle de chacun des messages! Pour cela, nous allons utiliser le DataLoader de PyTorch dans lequel nous pouvons tokenizer les messages grâce à une collate_fn:
def tokenize_batch(samples, tokenizer):
text = [sample["Utterance"] for sample in samples]
labels = torch.tensor([sample["Label"] for sample in samples])
str_labels = [sample["Dialogue_Act"] for sample in samples]
# The tokenizer handles
# - Tokenization (amazing right?)
# - Padding (adding empty tokens so that each example has the same length)
# - Truncation (cutting samples that are too long)
# - Special tokens (in CamemBERT, each sentence ends with a special token </s>)
# - Attention mask (a binary vector which tells the model which tokens to look at. For instance it will not compute anything if the token is a padding token)
tokens = tokenizer(text, padding="longest", return_tensors="pt")
return {"input_ids": tokens.input_ids, "attention_mask": tokens.attention_mask, "labels": labels, "str_labels": str_labels, "sentences": text}
Récupérons les trois splits du dataset, qui nous seront utiles dans la seconde partie de l’atelier:
train_dataset, val_dataset, test_dataset = dataset.values()
Nous pouvons maintenant créer un DataLoader pour l’ensemble de validation sur lequel nous allons travailler:
val_dataloader = DataLoader(val_dataset, collate_fn=functools.partial(tokenize_batch, tokenizer=tokenizer), batch_size=16)
next(iter(val_dataloader))
{'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]]),
'input_ids': tensor([[ 5, 6858, 152, ..., 1, 1, 1],
[ 5, 1034, 11, ..., 1, 1, 1],
[ 5, 895, 6, ..., 1, 1, 1],
...,
[ 5, 30, 44, ..., 1, 1, 1],
[ 5, 69, 45, ..., 1, 1, 1],
[ 5, 159, 178, ..., 1, 1, 1]]),
'labels': tensor([ 5, 1, 17, 7, 1, 24, 7, 1, 30, 7, 21, 5, 1, 17, 7, 1]),
'sentences': ['Bravo! Vous avez été rapides!',
"Qu'est-ce que je peux faire pour vous?",
'merci',
"Eh bien, il va falloir la fabriquer cette manette. Allez voir Mélissa, la responsable d' îlot de production, elle va vous aider. Elle doit être dans l' atelier de fabrication.",
"Mais sinon, vous avez encore des questions sur l'entreprise ? Le staff de l'entreprise, ou bien les études qu'ils ont fait ?",
"j'ai un peu de temps... allez y dites moi en plus sur l'entreprise, le staff et sur les études de chacun...",
"la plasturgie, c' est plus une question de logique que de force physique. que ce soit pour imaginer les produits de demain comme ici, au bureau d' études, ou pour les créer, comme dans l' atelier, tout le monde y trouve son compte, filles comme garçons Il y a tellement de métiers différents et intéressants.",
"et vous vouliez savoir quelles études ils avaient fait c'est ça ?",
'oui oui',
"Il y a des métiers pour tout le monde\xa0du BEP à l' ingénieur. mais en fait, peu importe le niveau d' études\xa0il y a toujours des possibilités d' évolution.",
'Bon, je dois vous laisser. Bon courage pour la suite !',
'Bravo! Vous avez été rapides!',
"Qu'est-ce que je peux faire pour vous?",
'est ce que je peux utiliser la manette maintenant ?',
"Il ne vous reste plus qu' à trouver les composants électroniques pour terminer cette manette. Sophia doit les avoir sur elle, je l' ai vue passer tout à l' heure.",
'Mais avant de partir, voulez vous faire un mini quizz avec moi ?'],
'str_labels': ['greet',
'ask',
'next_step',
'inform',
'ask',
'staff_enterprise',
'inform',
'ask',
'yes',
'inform',
'quit',
'greet',
'ask',
'next_step',
'inform',
'ask']}
Le DataLoader récupère des batchs de 16 phrases avec leurs labels, les tokenise, et renvoie un dictionnaire contenant tout le nécéssaire pour CamemBERT.
Nous allons itérer dans ce DataLoader afin de récupérer une représentation pour chacune des phrases du dataset:
sentences = []
labels = []
str_labels = []
all_representations = torch.Tensor()
with torch.no_grad():
for tokenized_batch in tqdm(val_dataloader):
model_output = camembert(
input_ids = tokenized_batch["input_ids"],
attention_mask = tokenized_batch["attention_mask"],
output_hidden_states=True
)
batch_representations = average_embeddings(model_output["hidden_states"][-1], tokenized_batch["attention_mask"])
sentences.extend(tokenized_batch["sentences"])
labels.extend(tokenized_batch["labels"])
str_labels.extend(tokenized_batch["str_labels"])
all_representations = torch.cat((all_representations, batch_representations), 0)
0%| | 0/59 [00:00<?, ?it/s]
L’inférence a pris un peu plus de 3 minutes. C’est long, n’est-ce pas ? C’est normal: nous n’avons pas utilisé le GPU mais le CPU pour réaliser l’inférence sur ces 59 batchs!
Pour utiliser le GPU, il suffit d’utiliser la méthode .cuda() sur les tenseurs et le modèle afin de transférer les poids sur cet accélérateur matériel:
camembert = camembert.cuda()
sentences = []
labels = []
str_labels = []
all_representations = torch.tensor([], device='cuda')
with torch.no_grad():
for tokenized_batch in tqdm(val_dataloader):
model_output = camembert(
input_ids = tokenized_batch["input_ids"].cuda(),
attention_mask = tokenized_batch["attention_mask"].cuda(),
output_hidden_states=True
)
batch_representations = average_embeddings(model_output["hidden_states"][-1], tokenized_batch["attention_mask"].cuda())
sentences.extend(tokenized_batch["sentences"])
labels.extend(tokenized_batch["labels"])
str_labels.extend(tokenized_batch["str_labels"])
all_representations = torch.cat((all_representations, batch_representations), 0)
0%| | 0/59 [00:00<?, ?it/s]
Avec le GPU, l’inférence dure 4 secondes: voilà qui est mieux! Il est maintenant temps de visualiser ces représentations et de voir si des clusters apparaissent naturellement.
Nous pourrons notamment voir si les représentations de CamemBERT nous permettent d’attribuer directement le label souhaité aux messages.
Les représentations de Camembert sont simplement les outputs vecteurs du modèle comme illustré ici:
Pour cela, commençons par projeter les représentations en deux dimensions à l’aide d’un TSNE:
from sklearn.manifold import TSNE
tsne = TSNE()
all_representations_2d = tsne.fit_transform(all_representations.cpu())
Nous pouvons maintenant représenter nos phrases en deux dimensions, et associer à l’aide d’une couleur le label correspondant:
scatter_plot = px.scatter(x=all_representations_2d[:, 0], y=all_representations_2d[:, 1], color=str_labels)
scatter_plot.show(config={'staticPlot': True})
On distingue quelques groupes (ou clusters), mais on se rend bien compte que les représentations du modèle ne permettent pas de classifier correctement les messages selon les labels définis.
Pour découvrir comment finetuner un modèle “général” comme CamemBERT sur cette tâche de classification, rendez-vous dans la deuxième partie de ce tutoriel.